Mission
定制知识库 + 大语言模型 = 私人AI应用
在这个以数据和技术驱动的时代,我们理解每个人和每个企业都有其独特的需求和挑战,这正是我们开发私人AI应用的出发点。
我们的使命是通过结合定制知识库和大语言模型,为每位用户打造一个完全个性化的AI体验。
私人AI的核心在于个性化,我们不仅仅是在提供一个工具或服务,而是在为您打造一个理解您的AI伙伴。
这意味着,无论您是一位需要针对特定市场趋势作出快速决策的商业领袖,还是一名寻求最新科研资料的学者,您的私人AI都能够根据您的具体需求来定制信息和回答。
我们的目标是让私人AI应用成为您最值得信赖的知识伙伴,帮助您在信息海洋中快速定位,获取精准、及时、个性化的洞见。
通过私人AI,我们希望能够帮助每个用户实现他们的个人或职业目标,推动他们向更高的成就迈进。
Why?
来自客户的困惑
2023年6月25日,我们成功推出了Lab-GPT项目,这是一个融合了多种大型语言模型的先进AI工具。
自上线以来,Lab-GPT已经吸引了超过80,000名注册用户,并广受客户好评和认可。
在助力工作和学习的方面,Lab-GPT展现了显著的效能,不仅显著提升了效率,更是改变了人们的工作和学习模式。
这个项目的成功不仅体现在用户数量的增长,更重要的是它在提高日常任务处理效率和促进知识获取方式上的革新性贡献。
自Lab-GPT项目上线以来,我们团队致力于积极协助客户解决他们在使用过程中遇到的各种问题。
我们发现,通过优化查询提示(prompt),许多问题能够得到高质量的答案。然而,在某些情况下,我们也遭遇了挑战:有些问题超出了模型本身的知识范畴,导致无法提供准确答案,甚至出现了误导性的信息。
面对这些局限性,我们寻求了新的解决方案。通过构建个性化的知识库,能够显著拓展模型的知识边界,从而克服这些挑战。
这种创新的思路催生了我们目前的私人AI应用项目,它旨在提供更加精准、个性化的知识服务,以满足用户的特定需求。

在推进我们的私人AI项目时,我们深入研究了多个专业领域中用户经常面临的具体问题。
这些问题不仅限制了用户获取专业信息的能力,而且在很大程度上影响了他们的决策和体验。
- 医疗领域:
- 用户常常提出关于健康和治疗的复杂问题,但通用AI模型在提供具体、最新医学研究或药物信息方面存在不足。例如,一个特定药物的副作用或最新的治疗方案,这些问题需要依赖最新的医学知识库来准确回答。
- 这种信息的缺乏可能导致用户无法获得对他们健康决策至关重要的信息,增加了做出不当决策的风险。
- 法律领域:
- 用户可能需要了解特定法律问题的细节,如商业合同法或知识产权法的最新法律解释。然而,传统的AI模型往往不能提供足够深入或最新的法律信息。
- 法律信息的不精确或过时可能导致企业和个人在法律合规和决策上犯错误,从而承担不必要的法律风险。
- 科研学术领域:
- 在科研和学术界,研究人员和学者经常需要访问最新的研究成果、论文和科学发现。然而,常规的AI模型在提供最新、专业的学术资源方面往往存在局限。
- 对于科研人员来说,知识图谱的建立非常重要,传统AI模型在知识库和关系上可能存在的缺失,让使用者无法获得完整可靠的信息。
通过探究这些痛点,我们明确了专业知识库的必要性和构建私人AI的目的。
我们的目标是解决这些具体问题,提供一个更加精准、专业和可靠的AI解决方案,帮助用户在各自的专业领域做出更好的决策。
What?
RAG技术:专业知识库的核心
解决方案的核心是RAG(Retrieval-Augmented Generation)技术,一种先进的自然语言处理方法,旨在增强和提升大语言模型的效能。
RAG的工作原理基于一个关键概念:结合传统的大语言模型(如GPT)的生成能力与专门的信息检索系统。
这意味着,当提出一个查询时,RAG首先从一个定制化的、经过优化的知识库中检索相关信息,然后将这些信息作为参考,指导语言模型生成更准确、更专业的回答。
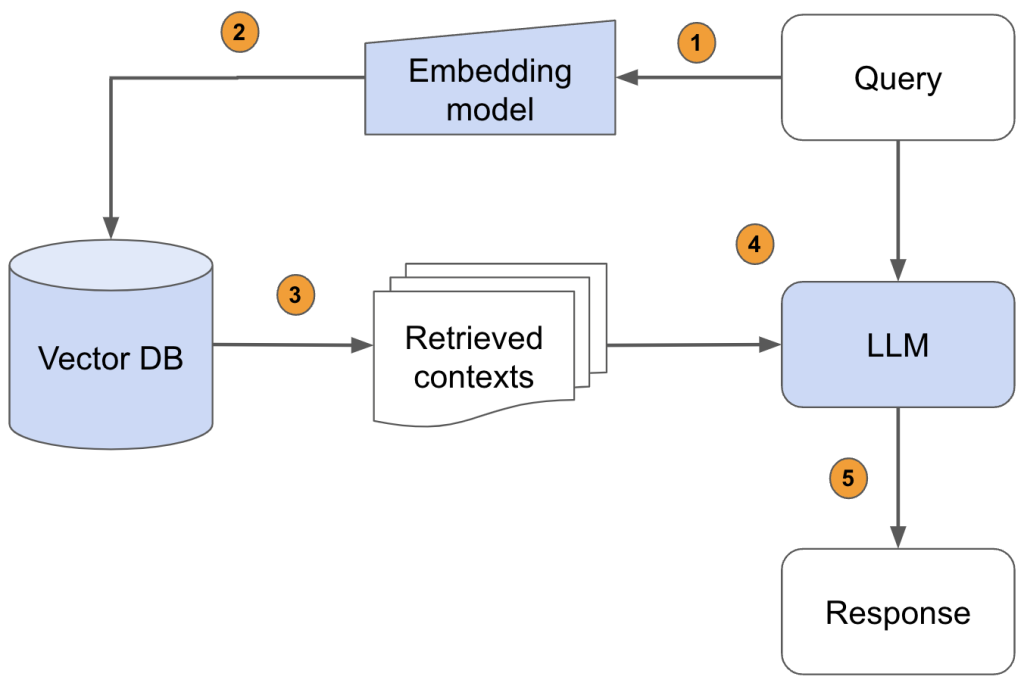
这一过程的关键在于两个阶段的协同作用。
首先,检索阶段通过精确匹配查询与知识库中的相关信息,确保提供的内容是专业和具体的。
其次,生成阶段利用大语言模型的强大语言处理能力,将检索到的信息转化为流畅、自然的文本回答。
这种结合不仅提升了回答的专业水平,而且保持了回答的连贯性和可读性。
RAG技术的应用,特别是在处理专业或行业特定的查询时,意味着我们能够提供远超传统AI模型的精准度和相关性。
例如,在金融分析领域,RAG能够从最新的市场报告中提取关键数据,然后生成深入的市场趋势分析;在医疗领域,它可以引用最新的医学研究来回答复杂的健康咨询。
How?
如何实现:数据处理和技术集成
数据处理:
- 数据收集:
- 收集个人专业领域的原始数据,如专业论文、行业报告、市场分析等。
- 确保数据的多样性和广泛性,以覆盖该专业可能遇到的各种情况。
- 数据清洗:
- 识别和修正错误数据,如去除重复、纠正错误的格式或分类。
- 使用自动化工具和手动审核相结合的方法,确保数据质量。
- 数据分类:
- 根据用户需求或行业特点对数据进行分类。
- 使用机器学习算法来帮助识别数据的关键特征和类别。
- 数据适配与拆分:
- 将数据适配为适合模型处理的格式,将文本转换为统一的结构化格式。
- 拆分大型数据集,确保每个部分都易于处理且信息丰富。
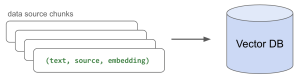
技术集成
- 数据嵌入(Embedding):
- 将处理过的数据转化为嵌入向量,便于大语言模型检索和处理。
- 使用先进的嵌入技术,确保数据向量具有高度的可检索性和相关性。
- 集成到大语言模型:
- 将嵌入向量集成到大语言模型中,使模型能够访问和利用这些数据来生成答案。
- 确保模型的适应性,使其能够根据不同的查询需求灵活使用这些数据。
- 技术整合与解决方案:
- 整合技术实现数据一致性、模型训练的复杂性和数据安全性。
- 解决方案包括使用高级数据同步工具、采用分布式训练方法和实施严格的数据保护措施。

通过这些细致的步骤,我们确保了私人AI应用在提供定制化、专业的答案方面具有卓越的能力,同时也保障了整个系统的可靠性和安全性。这一过程不仅是技术上的挑战,更是我们对用户体验和专业准确性承诺的体现。
Example
举例,调用两个窗口,一个是通用GPT,一个是RAG+GPT
定制专业知识库,开始使用你的私人AI