
想象一下,一位专业音乐家能够在不弹奏任何乐器的情况下探索新的作品。或者一位独立游戏开发者用微乎其微的预算在虚拟世界中填充逼真的音效和环境噪音。或者一位小企业主轻松地为他们最新的Instagram帖子添加配乐。这就是AudioCraft的承诺——我们的简单框架,可以从文本输入生成高质量、逼真的音频和音乐,训练过程是在原始音频信号上进行,而不是MIDI或钢琴卷。
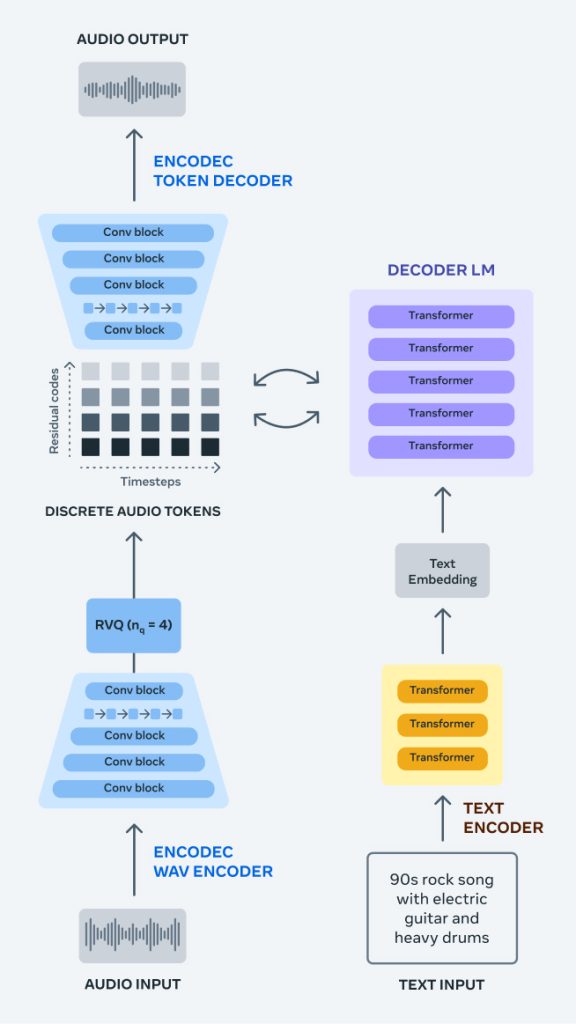
AudioCraft由三个模型组成:MusicGen、AudioGen和EnCodec。MusicGen使用Meta拥有的和特别许可的音乐进行训练,从文本输入生成音乐,而AudioGen则在公开的音效上进行训练,从文本输入生成音频。今天,我们很高兴发布我们的EnCodec解码器的改进版本,它允许以更少的人工制品生成更高质量的音乐;我们预训练的AudioGen模型,它让你可以生成环境声音和音效,如狗吠、汽车鸣笛或木地板上的脚步声;以及所有的AudioCraft模型权重和代码。这些模型可供研究目的使用,以进一步了解这项技术。我们很高兴能让研究人员和实践者首次接触到,他们可以用自己的数据集训练自己的模型,帮助推动技术的发展。
AudioCraft的模型家族能够产生高质量的音频,具有长期的一致性,而且可以通过自然的界面轻松地与之交互。有了AudioCraft,我们简化了与领域内先前工作相比的音频生成模型的整体设计——让人们可以完全使用Meta过去几年开发的现有模型的全部配方,同时也赋予他们推动极限和开发自己模型的能力。
AudioCraft适用于音乐和声音的生成和压缩——所有这些都在同一个地方。因为它易于建立和重用,想要构建更好的声音生成器、压缩算法或音乐生成器的人都可以在同一个代码库中完成,建立在他人的工作之上。
我们的团队正在继续研究高级生成人工智能音频模型背后的研究。作为这次AudioCraft发布的一部分,我们还提供了新的方法来通过基于扩散的方法进行离散表示解码,推动合成音频的质量。我们计划继续研究更好的生成模型的可控性,探索额外的条件方法,并推动模型捕获更长范围的依赖性。最后,我们将继续研究这些模型在音频上训练的限制和偏见。
我们看到AudioCraft模型家族作为音乐家和声音设计师专业工具箱中的工具,它们可以提供灵感,帮助人们快速头脑风暴,并以新的方式迭代他们的作品。
我们相信,将来,生成人工智能可以帮助人们大大提高迭代时间,让他们在早期原型设计和灰盒阶段更快地获得反馈——无论他们是大型AAA开发商为元宇宙构建世界,还是音乐家(业余的、专业的或其他的)正在创作他们的下一首作品,或者是一位小型或中型企业主希望提升他们的创意资产。AudioCraft是生成人工智能研究的一个重要步骤。我们相信,我们开发的简单方法成功地生成了强大、连贯、高质量的音频样本,将对发展先进的人机交互模型产生有意义的影响,考虑到听觉和多模态接口。我们迫不及待地想看到人们用它创造出什么。
从文本描述生成音频:
文本提示:警报器和嗡嗡作响的发动机接近并通过
文本提示:流行舞曲,带有朗朗上口的旋律、热带打击乐和欢快的节奏,非常适合海滩
文本提示:大地色调、环保意识、尤克里里琴注入、和谐、轻松、随和、有机乐器、柔和的律动
原文链接:点击这里